

Our AI runs locally on your phone
Our local LLMs provide absolute privacy for your Brainstorms

I’m excited to share an update about one of our most requested features: local LLM support for Brainstorms. For those who've been asking: yes, your AI conversations can now run entirely on your device, giving you complete control over your data. This feature is currently available to our paying subscribers, starting at 1.99 per month, and today I want to cover why we made that choice and what it means for the future of private AI conversations.
The Privacy Promise We're Keeping
In an era where every interaction seems to flow through someone else's servers, we believe users should have the choice to keep their thoughts truly private. Local LLMs represent more than just a technical feature. They are a commitment to user autonomy. When you run a Brainstorm locally, your ideas, questions, and conversations never leave your device. No cloud processing, no data transmission, no third-party access. It's AI assistance that respects your boundaries, because your midnight brainstorming session about the novel you're writing or your business strategy thoughts should remain yours alone.
What you can do today
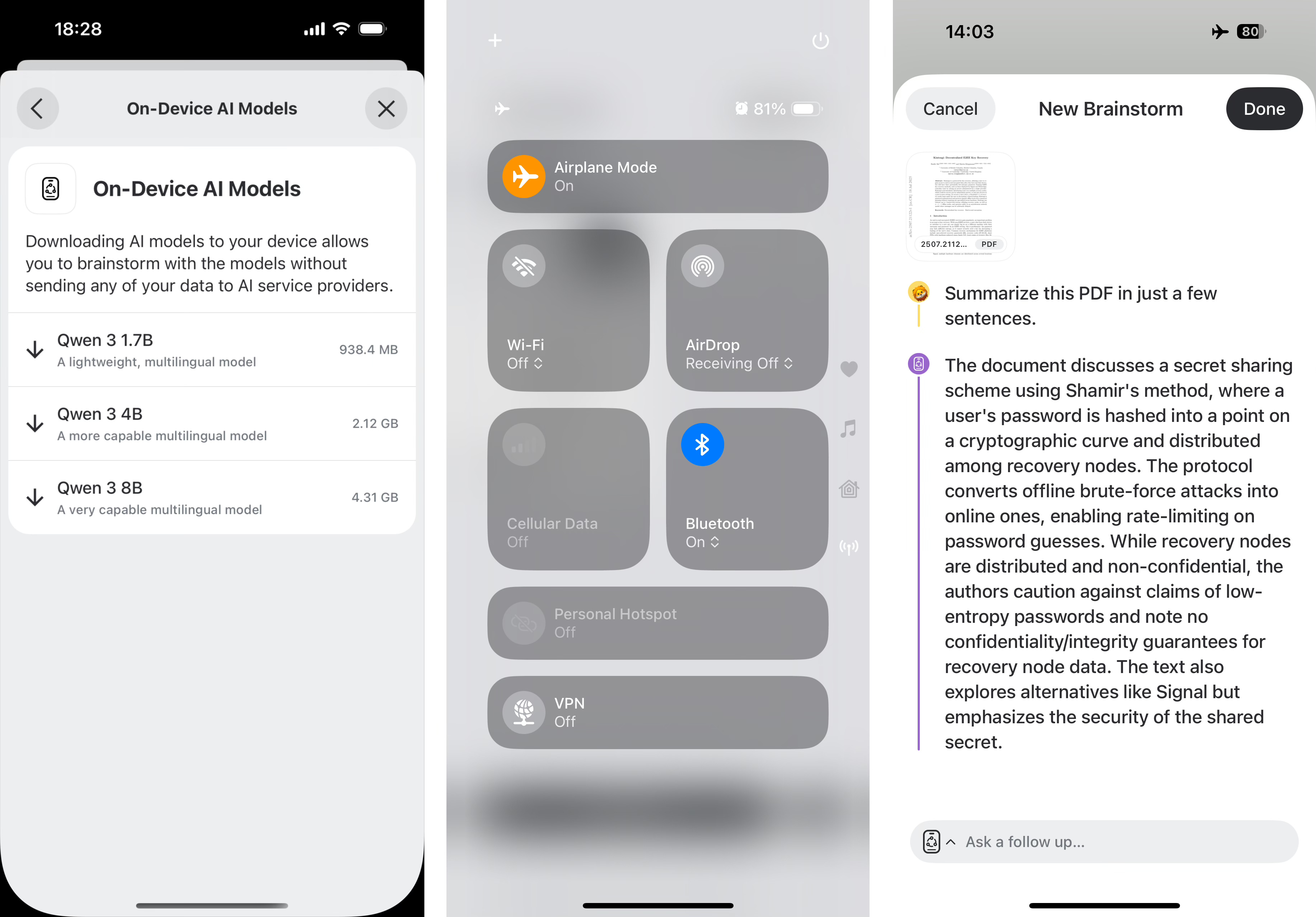
Download a local model by tapping on your name, “Integrations,” then “On-Device AI.” I recommend the Qwen 3 model today – the 4B (4 billion) version is a good model. It can help with creative writing, it can answer general fact questions, summarize documents, etc.
Not all models will be available on all devices. Some of the most powerful models require the newest and most powerful devices. If you have an older device or are low in disk space, the 1.7B will work, but will make more mistakes.
After downloading the model, go ahead and turn on Airplane Mode, then create a new Brainstorm. Having control over your data and being able to choose when to use online models vs offline is such a cool super power.
Some things I’ve been using Brainstorms for in the last month:
Language Learning Practice: Create conversations in the language you're studying, practice translations, or upload text files in foreign languages for help with comprehension. The AI can explain grammar, suggest more natural phrasing, or role-play everyday situations like ordering at a restaurant or asking for directions.
Code Review and Debugging Partner: Save code snippets as bookmarks or files, then use Brainstorms to rubber-duck debug, get suggestions for refactoring, or understand error messages. It's like having a patient senior developer available 24/7, even on airplane mode during a commute.
Recipe Development from Bookmarks: Save recipe bookmarks throughout the week, then use Brainstorms to plan meals, create shopping lists, or modify recipes based on dietary restrictions. Ask it to suggest ingredient substitutions or help you scale recipes up or down for different group sizes.
Local LLMs are currently for paid subscribers
At the moment, local models require a small monthly or yearly subscription. Why? Quality-assurance and uncertainty. Sure, you can download an app right now that will show you 100 different models to download, and most of which either are too small to do anything useful or will crash often depending on the context. That’s not good enough for us.
We only ship models we’ve benchmarked, stress-tested and optimized for battery life and thermals. We are putting in the lab time with all of our test phones.
The world of LLMs is changing quickly, different models ship with entirely new, incompatible architectures (Gemma 3 cannot run with code written for Gemma 2), and multi-modal capabilities are still evolving. We are keeping up and will make sure you get the latest, most capable, most efficient models on your device that actually work.
Opening up to the free tier is absolutely on the roadmap. We are committed to making the latest local LLMs work great on all the latest phones, and you can support our efforts at 1.99 per month or 19.99 per year.
Under the hood
Running a modern LLM locally isn’t plug-and-play. We ran into memory ceilings (the 8 GB RAM minimum for some models is real), thermal throttling, and bizarre bugs. Apple calls the same pain points “strict device requirements” for its Apple Intelligence rollout; Google engineers optimized Gemini Nano for their very latest Pixel phone with their custom chip first, then back-ported to older devices; and most of the tech giants are just relying on their datacenters to do the work, sending everything over the network each time.
If you are a programmer, you can checkout our open source SHLLM library on GitHub. As we solve problems and develop optimizations, we're committed to contributing back to the community that has made local AI possible. When we figure out how to make a model run 20% faster or use 30% less memory, that knowledge belongs to everyone.
Looking Forward: The Future is Local
We're just getting started. Our roadmap includes expanding model selection, improving performance across a wider range of devices, and eventually making basic local AI features available to all users. We're also exploring ways to let users bring their own models and customize their local AI experience even further. Privacy-conscious AI isn't a niche feature—we believe it's the future. As AI becomes more integrated into our daily lives, the ability to choose where our data is processed becomes not just important, but essential. We're building for that future, one optimized model at a time.
What are you Brainstorming today? Leave a comment or hit reply and let me know.
And happy sharing,
Nathan